模型压缩之pruning
Regularization of Neural Networks using DropConnect
- DropConnect主要是用来解决全连接过拟合问题的,是Dropout的通用实现。随着神经网络参数量越来越大,过拟合的风险越来越高,之前的一些经验是使用L1/L2以及Dropout。Dropout随机地将激活函数输出置0,导致每次参与训练的参数量变少,由于随机drop的关系,每次训练的网络都可能不一样,因此实际上我们训练的是多个子模型组成的混合模型。

Dropout
如果考虑激活函数为tanh和relu,则dropout的输出:
\[r=m*a(Wv)=a(m*(Wv))\]
inference时混合模型的输出:
\(o=E_{M}[a(M*(Wv))] \approx a(E_{M}[(M*W)v])=a(pWv)\)
\(M\)是\(m\)的repeat得到的矩阵。
DropConnect
随机地将全连接层的权重值置0,即输出为:
\[r=a((M*W)v)\]
\(M\)是与\(W\)大小一致的0-1矩阵,并且\(M_{ij}\)服从Bernoulli(p)分布。
inference时混合模型的输出:
\[o=E_{M}[a((M*W)v)] \approx E_{u}[a(u)] \]
where \(u\sim N(pWv, p(1-p)(W*W)(v*v))\)
注:对于\(u\)的分布论文中提到用高斯矩匹配估计,但也可以用中心极限定理进行估计

训练时的伪代码: 
inference时的伪代码: 
实验结果
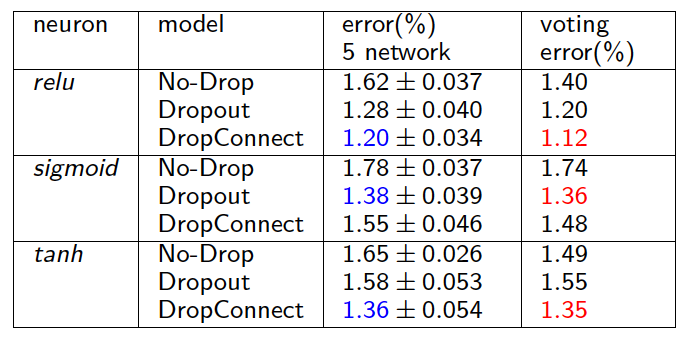
总结
DropConnect的初衷是解决过拟合问题的,DropConnect虽然在训练时可以将稠密矩阵乘转化成稀疏乘的方式,减少计算量,但在inference时还是需要完整的计算一遍,然后再利用正态分布多次采样后计算均值得到下一层的输入,因此inference的计算量反而增加了。论文给出的实验结果表明DropConnect在tanh和relu激活函数时会比dropout带来更低的测试错误率,sigmoid时会比dropout差点。DropConnect给模型压缩提供了一些思路,在训练时我们都倾向于选择更复杂的模型而需要非常大的计算量,DropConnect的做法表明这些复杂的模型实际上有大量的冗余,而去除这些冗余后并不会对模型产生任何伤害,反而会增强模型的泛化能力,因此在模型压缩中,对模型进行剪枝成了一个重要的研究方向。
##Learning bothWeights and Connections for Efficient Neural Network
作者首先关注到神经网络预测时的能耗问题,下面给出了一个45nm的CMOS处理器能耗表。

内存读取的能量消耗比其他数学指令高出三个数量级,因此论文提出对神经网络进行剪枝以压缩模型大小,减少内存读取消耗并降低计算量。剪枝不仅降低了模型复杂度,也减少了过拟合。除了剪枝,文中也提到可以借鉴HashedNets的方法进行模型参数共享,进一步降低模型大小。
模型剪枝分成三步:
1、正常训练模型,得到每个连接的重要程度(重要程度可以用权值的绝对值表示)
2、删除重要程度低的连接,将稠密网络转换成稀疏网络
3、使用保留下来的连接重训模型
第2步和第3步迭代进行。

正则化
关于正则化对剪枝结果的影响,论文给出的结论是:剪枝后重训前L1正则比L2效果好,但重训后L2比L1效果好。
Dropout Ratio调整
Dropout仍然被用来抑制过拟合,但是由于剪枝会减小模型大小,因此重训时Dropout ratio也应该更小。
\[D_{r}=D_{0}\sqrt{\frac{C_{ir}}{C_{io}}}\]
\[C_{i}=N_{i}N_{i-1}\]
其中\(D_{r}\)为重训的ratio,\(D_{0}\)为原始的ratio,\(N_{i}\)为第\(i\)层的神经元个数。
重训参数
由于神经网络的连续层往往保持耦合性,因此重训模型时最好保持连接的权重,而不是重新初始化。并且卷积层和全连接层的剪枝是交替进行的,对fc进行剪枝重训时需要保持conv不变,反之对conv进行剪枝重训时需要保持fc不变。
迭代剪枝
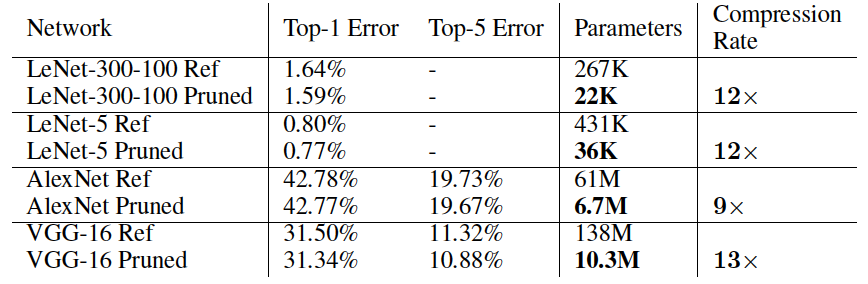
迭代剪枝的方式可以最大程度的压缩模型大小。在不损失效果的前提下,相比单次剪枝,多次迭代的方式可以将AlexNet的压缩率从5X提高到9X。
裁剪神经元
每次剪枝可以将那些没有输入连接或没有输出连接的神经元移除。无输出的神经元对最终模型结果没有任何影响,因此移除也不会对模型效果产生影响,而那些没有输入连接的神经元由于梯度下降和正则化最终也会变成无输出的神经元。
实验结果
文中将裁剪门限设置为一个质量参数乘以这一层权重的标准差,并在LeNet、AlexNet和VGG-16上进行了相关实验,卷积层也可以跟全连接层一样使用相同的剪枝策略,重训模型时会有一次调整学习率的过程,比如LeNet重训时学习率会衰减到原来的1/10,AlexNet会衰减至原来的1/100。
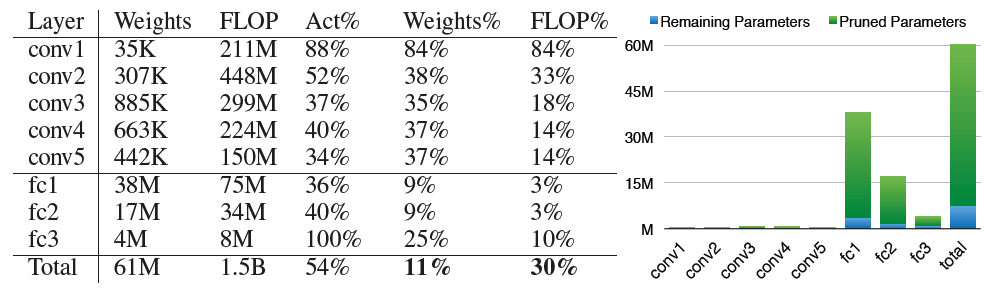
AlexNet各层的压缩情况:
剪枝与其他模型压缩方法的对比:

模型保存
稀疏矩阵在保存时需要同时保存indices,比如按照CSR格式保存时,我们除了保存所有的非零元素外,还需要保存每个元素对应的列号以及每行第一个非零元素在所有元素中的位置。为了压缩保存indices带来的开销,文中提到使用相对indices代替绝对indices,全连接层可以使用5bit来表示相对indices,而卷积层也可以只使用8bit。
总结
由于卷积层本身就是稀疏连接,相比fc对剪枝更敏感,因此剪枝方法对于全连接层的压缩率更高。剪枝只能压缩模型大小,但inference时并不会带来预测速度提升。intel在16年提出另一个剪枝与嫁接相结合的方法Dynamic Network Surgery for Efficient DNNs,进一步提高了剪枝方法的压缩率和重训收敛速度,此外2017年孙剑等提出了针对卷积层的Channel Pruning方法,可以结合此处的剪枝方法,应该可以达到更好的压缩效果。
##Channel Pruning for Accelerating Very Deep Neural Networks
