caffe学习总结
caffe学习总结
caffe的由来
caffe是贾扬清在UC Berkeley攻读计算机科学博士学位时开发的一套深度学习框架,由于高效、易读和模块化的设计,开源后经过nvidia的帮助优化和社区不断的完善,如今成为视觉领域主流的框架之一。
贾扬清其人
清华大学的本硕,UC Berkeley的计算机科学博士,师承Prof. Trevor Darrell,期间在新加坡国立大学、微软亚洲研究院、NEC美国实验室和google研究院实习和工作。博士毕业后一直在google brain担任研究科学家,致力于机器视觉、深度学习和tensorflow相关工作。2016年2月加入facebook,主导facebook大多数AI应用的通用、大规模机器学习平台(目前以caffe2为基础的caffe2go已经开源)。为什么要开发caffe
贾最早开发的是另一款软件Decaf,主要功能是基于cuda-convnet进行CNN训练。2013年贾扬清读博期间跟心理学老师合作研究使用概率框架来表达人的行为,"但是因为图像上提取的特征比较弱,所以可以外推的结果比较有限",而2012年Alex Krizhevsky提出的AlexNet在ImageNet比赛中大获成功,贾因此也希望将CNN应用到他们的心理学研究上,于是就开始写了Decaf,通过Decaf验证了"深度学习特征的优异的可移植性",因此就开始开发一套通用的深度学习框架,即后来的caffe。
caffe与其他一些主流框架的比较
caffe同期也存在其他一些开源框架,比如cuda-convnet、theano、torch等,并且后来又陆续开源了neon、mxnet、tensorflow、CNTK以及paddled等等。现在对于研究者,如何选择一个框架也成了一个麻烦的问题了。下图是2014年贾扬清在caffe论文中对当时的一些框架做的一个比较:

下面是近年主流框架的一个简单比较:
- 特性
| 主语言 | 从语言 | 硬件 | 分布式 | 命令式 | 声明式 | 自动梯度 | |
|---|---|---|---|---|---|---|---|
| caffe | C++ | Python/Matlab | CPU/GPU | ✖ | ✖ | ✔ | ✖ |
| mxnet | C++ | Python/R/Julia/Scala | CPU/GPU/Mobile | ✔ | ✔ | ✔ | ✔ |
| tensorflow | C++ | Python | CPU/GPU/Mobile | ✔ | ✖ | ✔ | ✔ |
| Torch | Lua | - | CPU/GPU/FPGA | ✔ | ✔ | ✖ | ✔ |
| theano | Python | - | CPU/GPU | ✖ | ✖ | ✔ | ✔ |
- 效率
caffe代码组织结构
caffe代码结构是非常清晰的,主要包含以下文件和目录:
- Makefile和Makefile.config
caffe支持cmake和make两种编译方式,不过大部分人只需要用make编译就可以了。Makefile.config可以对一些编译选项进行配置,比如USE_MPI、CPU_ONLY、DEBUG等等。
- include
在caffe中除了proto文件生成的头文件外,所有的c++头文件都放在include目录中。
- src
src与include的目录结构基本上相同,include目录中的文件基本上都能在src目录中找到对应的实现文件。
- tools
tools目录下是caffe提供给用户直接使用的接口,比如caffe.cpp用于模型训练、评估以及统计耗时,另外也提供一些数据集转换、计算均值等工具。
- examples
提供一些训练相关的脚本和网络配置,比如数据预处理脚本、不同的网络配置文件以及训练脚本。
- models
提供一些模型的网络配置文件,以及训练好的模型,用户可以直接用训练好的模型进行fine-tune或者分类。
- matlab/python
提供matlab和python的接口。
caffe网络的组织方式
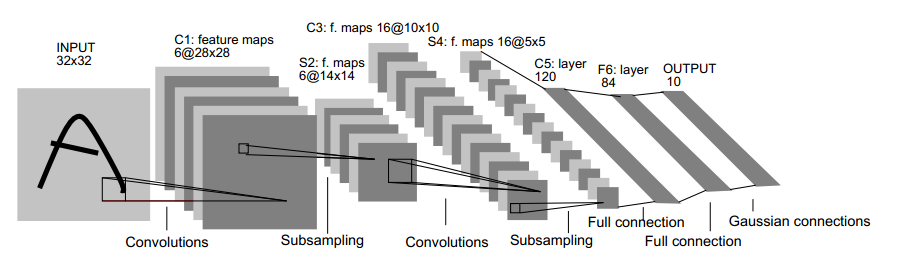
从LeNet开始,CNN就开始有了一个标准的分层结构——堆叠卷积层,卷积层可能后接一些normalization和pooling层,网络最后接一个或多个全连接层。由于梯度下降算法非常适合逐层计算,因此当时很多的通用框架都将网络(Net)抽象为多个数据处理层(Layer)组成的有向图,并支持灵活地定义网络结构。caffe将神经网络的训练问题分解为四个方面:数据、计算、流动控制以及问题求解,分别对应caffe中的Blob、Layer、Net和Solver。网络中流动的数据以及参数都用Blob来表示,Layer负责前向输出和后向梯度的计算,Net负责控制Layer计算的顺序,Solver是一个求解器的角色,根据Net的梯度对网络参数进行更新。
[待补充]
caffe中的Blob及同步策略
Blob是caffe中存储数据的基本结构,可以简单理解为一个4维的数组,数据组织格式为(N,C,H,W)。在caffe中上下层流动的数据和每层的权重参数都是用Blob来保存的,为了便于使用,Blob具有一些特性:
- Blob的内存是懒分配的(lazily
allocate),只有在真正使用的时候才会分配内存
- Blob会在CPU和GPU上各自分配一块相同大小的内存,便于在CPU和GPU之间进行切换
- 用户不需要关心CPU和GPU数据的同步,Blob会根据需要自动同步
下面是Blob的成员变量,data_是Blob存储的数据,diff_保存的是数据的梯度,shape_data_和shape_保存的都是当前数组的形状,count_是当前数据的大小,capacity_是申请的内存的大小,避免每次Reshape都要释放并重新申请内存。
1 | // include/caffe/blob.hpp |
下面主要说一下Blob的自动同步策略。首先看一下SyncedMemory的成员变量:
1 | // include/caffe/syncedmem.hpp |
head_的取值范围为UNINITIALIZED, HEAD_AT_CPU, HEAD_AT_GPU,
SYNCED。初始化时head_值为UNINITIALIZED,当调用Blob的取值函数时都会调用一次SyncedMemory的to_cpu或者to_gpu进行数据的同步,同步策略为:
1、取cpu数据时,会调用to_cpu函数,如果heda_为HEAD_AT_GPU,则需要将GPU的数据同步至CPU,否则不需要同步
2、取gpu数据时,会调用to_gpu函数,如果heda_为HEAD_AT_CPU,则需要将CPU的数据同步至GPU,否则不需要同步
head_标志的赋值:
1、每次调用SyncedMemory的mutable_cpu_data时,head_都会被置为HEAD_AT_CPU
2、每次调用SyncedMemory的mutable_gpu_data时,head_都会被置为HEAD_AT_GPU
3、每次同步之后heda_会被置为SYNCED。
因此Blob通过判断每次修改的位置来自行决定是否需要对不同设备间的两份数据进行同步,使用时就像只有一份数据一样,非常方便。
caffe中的Layer
layer是caffe模型的主要组成部分和基本的计算单元,与很多框架中的operator对应,一个典型的layer在forward时从下层连接获取输入,经过计算后输出到上层,backward时又从上层连接获取误差,计算本层梯度和误差后,将误差传递到下层连接。因此基类Layer实现了三个基本函数setup、forward和backward。
- setup:根据下层连接和配置参数完成本层参数的初始化,以及输出blobs的初始化
- forward:前向计算过程,并计算本层的loss
- backward:后向计算过程,并将本层误差传递到下层
forward和backward里面都会对CPU和GPU进行分支,如果是CPU模式,则真正参与计算的是forward_cpu和backward_cpu,如果是GPU模式,则参与计算的是forward_gpu和backward_gpu,并且在基类中forward_gpu和backward_gpu分别调用的是forward_cpu和backward_cpu,当然用户在定义新的layer时可以自行实现forward_gpu和backward_gpu。
基类Layer的成员变量:
1 | // include/caffe/layer.hpp |
layer_param_是从protobuf文件中反序列化得到的,存放的是layer的配置参数
phase_指示是训练还是测试
blobs_是本层的参数,比如权重和偏置
param_propagate_down_为每一个参数设定是否需要计算梯度
loss_是本层的损失值,loss层每个输出blob都有一个损失值,非loss层损失为0
由基类Layer直接或间接派生出各种layer,比如卷积(convolution)、全连接(fully connected或者inner product)、dropout、pooling、relu、softmaxWithLoss等等,每一个派生layer都会强制实现forward_cpu和backward_cpu。早期的caffe将layer分成5类,
- dataLayer类: 各类数据读取的接口
- neuronLayer类: 各种激活函数、dropout
- visionLayer类: 卷积层、采样层等2D图像相关的运算
- commonLayer类:全连接层和其他运算
- lossLayer类:实现各种代价函数
不过目前最新版本的caffe已经取消了visionLayer和commonLayer的分类。此外由于caffe使用了cuDNN运算加速库,因此部分layer有caffe和cuDNN两种实现,使用时可以通过protobuf文件配置需要使用的engine。
为了保持框架的可扩展性,大多数框架在layer或者operator的实现中使用了工厂模式,使用统一的工厂类来对不同的layer或operator进行实例化。下面是caffe使用工厂模式的代码实现,
1 | // include/caffe/layer_factory.hpp |
1 | // src/caffe/layer_factory.cpp |
caffe中的Net
Net是由Layer组成的有向图,表示整个神经网络的拓扑结构,与很多框架中的graph对应,一般用一个protobuf文件来定义。而且Layer作为有向图中的一个组件,是无法感知自己的上层和下层连接的,需要Net将数据feed给Layer,这样数据在有向图中才能真正流动起来。因此Net至少需要提供构建一个有向图和feed数据流两种功能。
- 构建一个有向图:void Init(const NetParameter& in_param)
- feed数据流: const vector<Blob<Dtype>*>& Forward(Dtype* loss)和void Backward()
在构建有向图时,caffe首先会对不符合规则的layer进行过滤,比如对于test net,则会把只用于train的layer过滤掉。对于有向图中可能存在分支的情况,caffe会自动插入split层,将原输入blob复制多份,分别输入不同的分支,比如:LeNet网络中的数据层的label需要输入到accuracy层和loss层,那么需要在数据层再插入一层,如下图所示。

Net会根据网络结构逐层创建layer,并指定输入输出blobs,以及是否需要backward。
1 | // src/caffe/net.cpp:Init |
在训练时,train net会首先初始化,test net之后初始化,每次test时会调用ShareTrainedLayersWith共享train net的参数,这样做可以节省显存并且避免不必要的数据拷贝。
需要注意的是,在protobuf文件中声明网络结构时,必须依照从下到上的顺序一层一层定义网络参数,而且test net和train net对应层的name最好一致(虽然不一致可能不会导致程序报错),因为test net与train net是根据匹配name进行参数共享的,如果name不一致则会导致无法进行参数共享,增加显存消耗的同时还会导致test结果不正确。
当有向图构建完成后,我们只需要调用Forward和Backward,数据就能流经整个网络,得到每层的输出、loss和每个参数的梯度。
1 | // src/caffe/net.cpp |
caffe中的Solver
前面讲到Net通过调用Forward和Backward可以得到每个参数的梯度,而Solver的主要作用就是根据这些梯度进行网络参数的更新。由于caffe将Net作为Solver的底层实现,因此Solver也就成了控制整个训练过程的中枢。Solver提供三个主要函数:Init、Solve、ApplyUpdate。
- Init:创建训练网络和测试网络,初始化一些参数
1 | // src/caffe/solver.cpp |
- Solve:调用Step进行迭代训练,每次迭代后都会调用ApplyUpdate进行参数的更新
1 | // src/caffe/solver.cpp |
- ApplyUpdate:调用对应的solver进行参数更新,下面是sgd solver的ApplyUpdate函数
1 | // src/caffe/solvers/sgd_solver.cpp |
由于梯度下降算法发展出了非常多的优化算法,目前caffe提供了六种优化算法来求解最优参数,在solver配置文件中,通过设置type类型来选择。
- Stochastic Gradient Descent (type: "SGD"),
- AdaDelta (type: "AdaDelta"),
- Adaptive Gradient (type: "AdaGrad"),
- Adam (type: "Adam"),
- Nesterov’s Accelerated Gradient (type: "Nesterov"),
- RMSprop (type: "RMSProp")
caffe断点保存和恢复
由于训练过程往往非常耗时,为了能够在突发情况后快速恢复训练,caffe提供了断点保存和恢复的功能,在solver的配置文件中可以配置保存的频率及保存时文件名的前缀,一个比较完整的solver配置文件如下:
1 | // solver.prototxt |
当然还有一些其他的参数,比如正则化类型和模型保存文件格式等,都会使用在proto文件中定义的默认值,具体查看src/caffe/proto/caffe.proto文件中的SolverParameter。
为了实现断点保存和恢复,caffe在Solver中加入了Snapshot和Restore,分别进行模型保存和模型恢复,相应地,在Net中也加入了ToProto/ToHDF5和CopyTrainedLayersFromBinaryProto/CopyTrainedLayersFromHDF5。Solver调用Step进行训练的时候,每次参数更新结束都会判断是否需要保存模型。
1 | // src/caffe/solver.cpp:Step |
Solver中Snapshot对模型参数和训练状态进行保存,模型参数提供两种保存格式——binary protobuf和hdf5。如果是protobuf格式,则会调用Net的ToProto,否则调用ToHDF5。
1 | // src/caffe/net.cpp |
Solver在开始训练时会尝试调用Restore进行断点恢复,根据文件名后缀判断文件格式,并选择RestoreSolverStateFromHDF5还是RestoreSolverStateFromBinaryProto。
1 | // src/caffe/solver.cpp:Solve |
in-place计算
为了节约显存,caffe支持原址计算,就是输入与输出都是同一个blob。如果前一层的输出和本层的输入都与后向计算时无关,而且本层的输入和输出blob大小相同,就可以使用in-place计算,比如卷积层后面的Sigmoid、Relu等都可以用同址计算,而BatchNorm层也支持in-place计算,是因为BatchNorm在实现时会将输入数据进行备份。使用同址计算只要在protobuf文件中指定该层的top和bottom是同名的就可以了,比如:
1 | layer { |
参数初始化方法
由于神经网络的目标函数往往是非凸的,参数初始化会对最终的收敛结果造成非常大的影响。为了满足不同的参数初始化需求,caffe提供了多种初始化方法,并且在net的配置文件中可以为每个参数选择一个初始化方法。比如下面的weight_filler和bias_filler:
1 | layer { |
在include/caffe/filler.hpp中caffe提供如下的初始化方法:
- constant:常量初始化,参数所有的值都被初始化为相同的值
- uniform:均匀初始化,参数的值按照指定区间均匀分布随机初始化
- gaussian:高斯初始化,参数的值按照指定均值和方差的正态分布随机初始化
- positive unitball
- xavier:本质上也是一种指定区间均匀分布的随机初始化方式,只是区间是通过参数大小计算得到
- msra:与xavier类似,不过使用的是指定均值和方差的正态分布随机初始化方式
- bilinear
多卡并行策略
为了提高效率,caffe支持单机多GPU并行训练,目前采用的是数据并行方式,暂不支持模型并行,为此caffe增加了一个P2PSync类,下面主要介绍一下P2PSync如何实现多卡并行的。
P2PSync封装了一个Solver负责训练,每张GPU都会对应一个P2PSync,并且P2PSync之间具有主从关系,它们之间构成一个二叉树的结构。在前向计算时,主P2PSync需要将模型分发给从P2PSync,而在后向传导时,从P2PSync就需要把梯度传给主P2PSync,主P2PSync会在聚合从P2PSync的梯度后传给更上一层的主P2PSync。在二叉树结构中,根节点P2PSync的Solver被叫做root solver,其他solver叫做worker solver,只有root solver才能进行参数更新,worker solver只是将梯度聚合并传递给root solver。
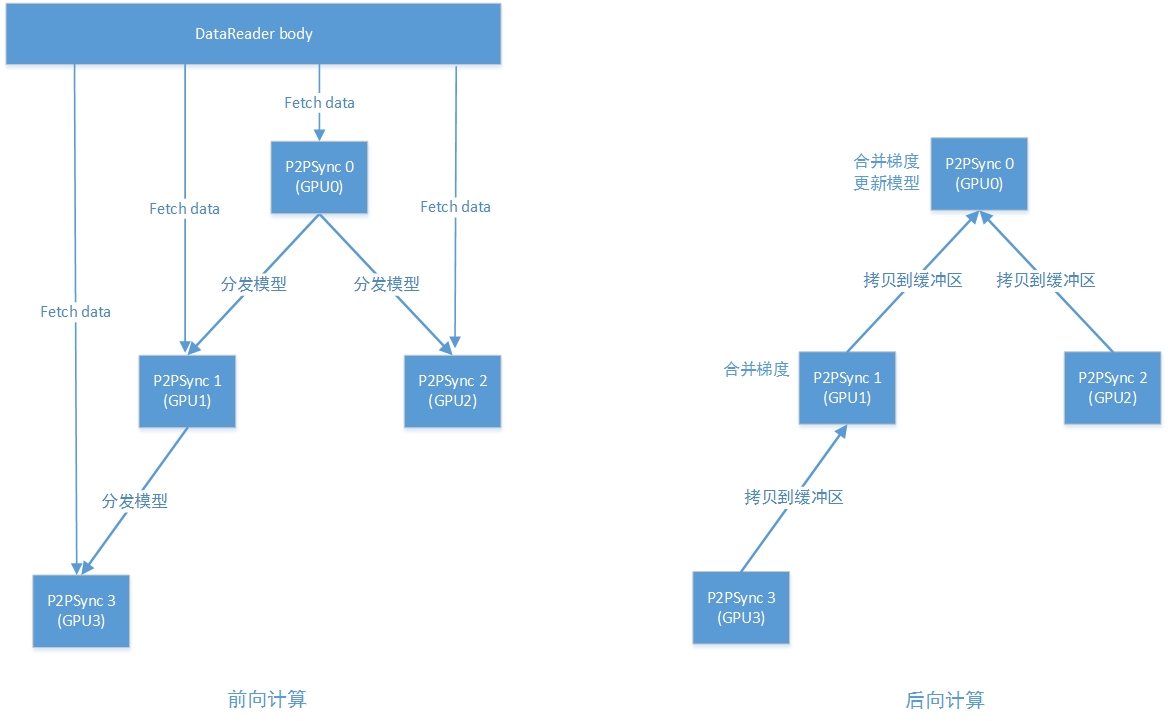
在P2PSync中主要的函数就InternalThreadEntry、on_start和on_gradients_ready。
1 | // src/caffe/parallel.cpp |
InternalThreadEntry是一个线程函数,Solver调用Step进行训练,在Step中每次前向计算前都会回调on_start获取最新模型,而在后向计算结束后又会回调on_gradients_ready传递梯度。
1 | // src/caffe/solver.cpp |
1 | template<typename Dtype> |
1 | template<typename Dtype> |
intel caffe多机并行策略
单机多卡的训练方式已经足够解决目前大部分模型训练的需求了,但随着数据量越来越大、模型越来越复杂,分布式异构计算成为行业通行的解决方案。BVLC caffe是不支持分布式训练的,intel有两个部门将caffe进行了再次开发以支持分布式和最新的Intel MKL-DNN,分别为intel caffe和caffe multinode。目前BML API已经支持intel caffe的模型训练、评估和预测了。
intel caffe采用的是数据并行的方式,但不同于目前主流的centralized parameter server通信模型,intel caffe借鉴了单机多卡的策略,采用的是一种all-reduce的binary tree模型,也就是将节点按照二叉树组织起来,每个父节点负责1-2个子节点和自己父节点的通信,相比一个中心的PS需要同时与其他多个节点通信的方式,这种binary tree方式将一部分PS的计算平均到了每个节点上,而且相同level的父节点之间可以并行,增加了梯度合并的并行度。
[待图]
为了更好地掩盖通信开销,子节点不需要等到整个模型的梯度都计算完才发送,而是每个layer计算完梯度后就会立即发送给父节点,父节点收到所有子节点的梯度后将本层的梯度合并后也可以立即发送给上一层的父节点。每个layer的参数会按照buffer的大小分成多个part,每个part都会异步地进行发送,当进行下一次迭代时,除了根节点的所有节点都会被阻塞,等待根节点将最终的梯度进行合并,并更新模型后发送给子节点。
除了分层通信外,intel caffe也支持梯度量化压缩,可以将全精浮点数编码成指定字节数的数值,减少节点间通信量。
intel caffe为了支持多种协议的通信,使用了boost的asio::io_service接口,底层实现支持MPI、TCP和UDP,不过目前只实现了MPI接口。
训练时交叉验证是在单节点(准确来说是根节点)上进行的,但每个节点上都需要存在验证集文件,这是因为即使不进行test,其他节点也会初始化test网络。
实战
参考
贾扬清自述http://www.yangfenzi.com/keji/59535.html
caffe官网http://caffe.berkeleyvision.org
http://ucb-icsi-vision-group.github.io/caffe-paper/caffe.pdf
https://www.zhihu.com/question/27982282
http://blog.csdn.net/myarrow/article/details/52064608
