阿里KunPeng框架学习
KunPeng是阿里最新公布的一个大规模机器学习框架,不仅包括了数据/模型并行、负载均衡、模型同步、稀疏表达、工业级容错等特性,而且还提供了易于使用的接口,在很多机器学习算法上都带来了非常大的性能提升。 原始论文 KunPeng: Parameter Server based Distributed Learning Systems and Its Applications in Alibaba and Ant Financial。
Introduction
主要对一些通用分布式计算框架进行比较。
Hadoop:只提供了一些粗粒度的操作,比如Map、Reduce和Join等。很多限制导致基于Hadoop的机器学习算法效率都非常低,这些限制包括中间结果会落盘、只能在shuffling阶段进行数据交换等。
Spark:使用RDD弥补了Hadoop的一些缺点,提供MLlib库,MLlib整合了很多机器学习算法,并且非常容易使用。但MLlib只支持中等规模的特征,计算和通信效率都比较低。一些公司使用第三方组件来弥补Spark的缺陷,但至今没有一个完美的方案。
GraphLab和GraphX:基于图的并行计算框架,允许用户进行细粒度的控制,但并不适合通用的机器学习算法,比如LR、深度学习等,并且也存在效率低的问题。
MPI:接口灵活高效,代码自由度比较高,比如在代码中所有进程之间可以随时通信。但使用MPI开发一个新算法的开销非常大,比如一个复杂的异步矩阵分解算法需要2000多行代码。MPI没有提供分布式ML平台通用的组件,比如分布式数据读取,内存管理和多线程并行的组件。更重要的是MPI没有提供单点失败的本地解决方案,根据他们的统计数据显示MPI作业在节点数越多时失败率越高。
parameter server框架:包含无状态的workers和有状态的servers,workers负责大部分的计算任务,servers负责保存和更新模型参数。servers可以定期将模型参数快照保存到一个缓存位置,一旦有节点失败,parameter server会自动从最新的checkpoint中恢复模型参数。parameter server框架只支持pserver和worker之间通信, 而pserver和pserver、worker和worker之间无法进行点对点通信,并且由于细粒度的接口导致用户编程比较复杂,因此现有的parameter server框架还存在几个问题:一是通信接口比较单一,没有MPI灵活;二是对于用户来说没有Spark易于编程使用。
正是由于上述框架的种种缺点,他们开发了一个产品级的分布式学习系统—KunPeng。KunPeng结合了parameter server和MPI的优点,提供鲁棒的failover机制,高效的稀疏数据通信接口和与MPI类似的通用接口,并且提供一个C++和Python的SDK,该SDK提供了一个类似单机的开发环境。KunPeng也与阿里的Apsara平台深度对接,提供ML的全工具集,包括基于SQL和MapReduce的数据预处理、预测、评估等等。
KunPeng整体架构
Apsara Cloud Platform
Apsara是阿里开发的一个大规模分布式操作系统,目前已运行在跨数十个机房的十几万台服务器上。下图中天蓝色部分就是Apsara的模块,白色部分为运行在Apsara之上的各种云服务,KunPeng就属于图中白色部分,运行在Apsara上,由Apsara提供任务调度和监控、文件系统等服务。
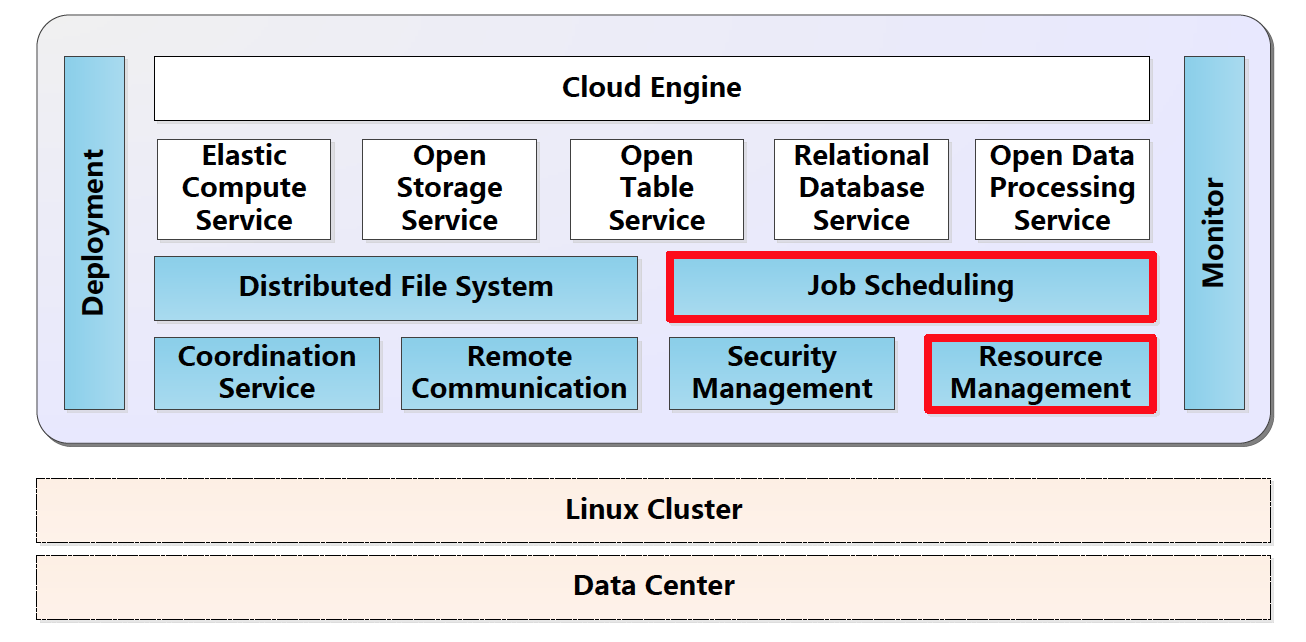 图中红色边框的任务调度模块和资源管理模块被统称为Fuxi(伏羲),Fuxi支持多种特性以保证系统的可扩展性和容错性,这些特性包括:增量资源管理协议、用户透明的失败恢复、故障点自动检测和多级黑名单机制。
图中红色边框的任务调度模块和资源管理模块被统称为Fuxi(伏羲),Fuxi支持多种特性以保证系统的可扩展性和容错性,这些特性包括:增量资源管理协议、用户透明的失败恢复、故障点自动检测和多级黑名单机制。
KunPeng Platform
KunPeng分为ML-Bridge和PS-Core两个子系统,ML-Bridge是KunPeng提供的高级编程模型,用户通过脚本编程的workflow可以方便地实现数据预处理、训练、预测和评估等算法,PS-Core是一个分布式键值对存储的paramter
server框架。  ML-Bridge由三个组件构成:
ML-Bridge由三个组件构成:
- 解释器。将用户的脚本解释为系统支持的算法
- 优化器。根据运行状态的历史统计和启发式方法,分析、调试和优化作业配置
- 执行器。根据作业的配置生成Fuxi调度的配置,提供整个作业生命周期的监控,并提供用户监控UI ML-Bridge简化了用户编程,比如一个算法流程包括数据入库与预处理、训练、评估和AB测试几个流程,在KunPeng中只需要调用下图中的几行命令就可以实现。整个流程对用户来说都是透明的,用户也不需要关心算法的具体实现和作业调度过程。

PS-Core不仅支持数据并行和模型并行,同时还支持模型同步更新(BSP)、ASP和SSP,稀疏表达和容错机制。 PS-Core在传统的worker和server基础上,增加了一个用于迭代控制的coordinator。coordinator声明了数据计算和参数更新的操作,构建了整个ML workerflows的作业图,并将这些作业调度到worker和server上运行,并参与servers和workers的failover过程。coordinator在迭代结束时会与Apsara的meta对迭代状态进行同步,并且由Fuxi监控管理,因此不存在SPOF(单点失败)的问题。
容错方案
KunPeng也给出了servers和workers的容错解决方案。对于servers,它们会异步地将参数快照保存到分布式文件系统,并且它们会在内存中对参数进行两备份,支持hot failover加速恢复过程。大多数情况下(比如接收到coordinator的恢复请求),servers可以立刻通过内存备份的参数中恢复。即使是servers或整个任务被中断或被kill,servers也可以通过最近一次保存的参数进行恢复训练。对于stateless的workers,failover非常简单,只需要从servers上pull对应的参数。对于stateful的workers,同样提供保存快照的接口,因此对于一些workers有本地状态的算法(比如LDA),faliover也非常简单。
总的来说,KunPeng的failover过程是当Fuxi检测到有节点失败时,重新调度新的节点,同时给coordinator发送异步节点失败的消息,coordinator接收消息后给servers和workers发送恢复请求,对于正常的servers接收请求后会直接从内存中恢复,而对于新调度的servers会从checkpoint中恢复,对于workers需要先从servers上pull对应的参数,stateful的workers还需要从保存的checkpoint中恢复状态。
DAG调度
这里的调度指的是coordinator对servers和workers的调度。由于coordinator节点会根据算法的workflow构建对应的作业DAG,并将DAG调度到servers和workers上进行执行。为了提高机器资源利用率和作业效率,DAG中相同深度的节点可以并行执行,比如下图中的Calculate for Block 0节点和Load Data for Block 1节点。通过DAG接口用户可以自定义IO操作、计算和通信过程,可以很方便地实现各种模型更新算法。

下图表示了PS-Core中bounded delay ASGD算法的C++实现,用户可以重写下面的Iterate函数实现自定义的算法。图中的mServerParam和mServerGrad对应servers上的模型参数和梯度,mWorkerParam和mWorkerGrad对应workers本地的模型参数和梯度,mSubDatasetPtr对应当前worker的数据子集。nSync为最大延迟迭代次数,nPull和nPush分别为从servers获取最新参数和将梯度发送给servers的频率。通过设置nSync、nPull和nPush可以很方便地在BSP和SSP之间切换,而去除SyncBarrier就成了ASP算法的实现。

负载均衡和通信接口
由于集群中机器的底层硬件和运行状态存在差异,因此一个任务的执行效率很大程度上取决于运行最慢的那个机器,针对这种情况可以有多种负载均衡的方法,比如可以对负载较高的机器分配更少的数据和计算量,PS-Core也为此设计了一个Backup instance机制。当某个节点被确定为慢节点时,coordinator会把慢节点标记为"dead"节点,请求Fuxi重新调度一个新的节点作为该节点的备份节点,并将该节点的负载转移到备份节点上。这种机制通常可以带来10%-20%的效率提升。
KunPeng对不同稀疏度和不同数据类型的数据通信做了深度优化,并且提供workers之间点对点的通信接口,比如AllReduce,ReduceTo和Bcast,这些灵活的通信接口使得KunPeng可以拓展更多的功能,比如模型并行。
FTRL
\[w_{t+1}=\mathop{\arg\min}_{w}\left(\sum_{s=1}^{t}g_{s}w+\frac{1}{2}\sum_{s=1}^{t}\delta_{s}{\Vert}w-w_{s}{\Vert}_{2}^{2}+\lambda_{1}{\Vert}w{\Vert}_{1}+\lambda_{2}{\Vert}w{\Vert}_{2}^{2}\right)\]
其中\(g\)为损失函数对\(w\)的梯度,\(\delta_{t}=\frac{1}{\eta_{t}}-\frac{1}{\eta_{t-1}}\),因此\(\sum_{s=1}^{t}{\delta_{s}}=\frac{1}{\eta_{t}}\),\(\eta\)为学习率,并且\(\eta_{t,i}=\frac{\alpha}{\beta+\sqrt{\sum_{s=1}^{s}{g_{s,i}^2}}}\),通常\(\alpha=1\),\(\beta\)是与数据集和特征相关的超参数。\(\lambda_{1}\)为L1系数,\(\lambda_{2}\)为L2系数。 更新公式为
\[w_{t+1}=\begin{cases}0& if\
{\vert}z_{i}{\vert}{\leq}\lambda_{1}\\
-(\frac{\beta+\sqrt{n_{i}}}{\alpha}+\lambda_{2})^{-1}(z_{i}-sign(z_{i})\lambda_{1})&
otherwise\end{cases}\] 下图表明了LR
FTRL-Proximal算法单机更新过程。

这个算法在单机时很容易实现,但在分布式环境必须要考虑通信效率、servers的负载和算法收敛性问题。考虑到BSP的低效和ASP可能不收敛的问题,他们使用了bounded delay的SSP更新方法,并且设置trust region来调节参数范围,避免模型发散。整个算法具体过程如下:
- workers本地保存了模型\(w\)和\(z\)、\(n\),\(z\)、\(n\)通过bounded-asynchronous的方式与servers保持同步
- workers加载数据,根据\(z\)和\(n\)更新本地模型\(w\),计算梯度并更新本地模型\(w\)和\(z\)、\(n\),同时使用\(\delta_{z}\)和\(\delta_{n}\)累加\(z\)和\(n\)的增量,在需要与servers同步的时候将累加的\(\delta_{z}\)和\(\delta_{n}\) push到servers
- servers合并所有workers发送的\(\delta_{z}\)和\(\delta_{n}\),最后更新全局\(z\)和\(n\)。
workers向servers传递\(z\)和\(n\)的增量,而不是直接传递模型梯度,这种做法虽然会带来一些通信开销,但降低了servers的计算负载,这是在通信效率和计算负载之间做的平衡。为了避免发散,servers在trust region下更新模型。trust region的策略有两种:一种是当模型中的元素超出置信阈时,直接回退整个模型;另一种是通过映射的方式将模型的值限制在置信阈中。

MART
MART(多增量回归树)又叫做GBDT,是一种应用比较广泛的机器学习算法。KunPeng实现了一个通用的MART算法,支持千亿级样本量和上千维的特征,并在MART的基础上实现了LambdaMART算法。
- MART 为了处理超大规模的数据量,KunPeng-MART使用数据并行的方式减少内存使用量,并采用了XGBoost的分布式加权直方图算法优化分裂点查找过程。具体来说就是,每个worker都保存了整颗树,在分割叶节点时, (1)每个worker使用分配的数据子集计算一个局部加权直方图,计算完成后将直方图push到servers (2)servers收到workers发送的直方图后,采用多路合并算法得到全局直方图,并找到最优分割点 (3)workers从servers pull分割点,分裂节点并将数据分到分裂后的叶节点
重复上述过程,可以得到整棵树。然后只要按照gradient boosting方法一棵一棵地建树,最终得到MART。随着特征维度和树深度的增加,查找分裂点过程中的计算和通信都可能成为性能瓶颈。为了解决这个问题,他们提到使用KunPeng的通信模式去减少合并局部直方图的开销,但并没有透露具体的方法。
- LambdaMART
LambdaMART建树的过程与上面的MART一样,不同的是LambdaMART计算一阶导数和二阶导数的方式。由于LambdaMART要求同一个query
group的训练数据按sample两两组成pair对,因此当训练数据不是按照query
group连续存储时就会存在问题。对于这个问题,他们提出了两种解决方法:
(1)先全局统计一下每个query id对应的样本总数,然后按照multiway number partitioning algorithm对query id进行分片,每个worker只加载属于自己的query ids对应的训练样本。
(2)第二种是近似的方法。首先要求相同query id的样本在文件系统中是连续存储的,然后每个worker还是按照正常情况加载属于自己的分片数据。如果相同query id的样本被分在两个不同的worker上,则会把这两个worker上相同query id的样本当做不同query id来处理。
其他算法
- Large-scale sparse Logistic Regression (LR)
实现了不同的优化算法,L-BFGS、OWL-QN和BCD,其中BCD算法是数据和模型同时并行的算法。
- Distributed Factorization Machines
workers异步计算梯度,使用AdaGrad优化算法
- Caffe
实现了Caffe和KunPeng的对接,a generalized CPU-based large-scale deep learning platform,简化DL算法开发
实验结果
下面的实验都是在一个拥有5000台服务器的正式集群上进行的,每台机器12个Intel Xeon CPU E5-2430 (2.2 GHz) CPU和96GB内存。
KunPeng、Spark和MPI的LR算法对比

不同平台的LR都采用L-BFGS算法更新,并且memory history parameter都设置为10,并且使用同一个集群相同的CPU资源,在7个不同的数据集上KunPeng在效率和内存占用上都取得非常明显的优势。
在另外一个18 billion样本和 7 billion特征的数据集上,他们统计了KunPeng在不同workers数量时的加速比。

KunPeng仅使用25个workers就可以训练这么大的数据,workers增加时依然能保持较高的加速比,并且内存占用随着workers增加而近乎直线降低。
KunPeng-MART和XGBoost的对比
下图分别为KunPeng-MAR和XGBoost在不同任务上的峰值内存占用和训练时间对比。


KunPeng-FM、LibFM和DiFacto的对比
下面是在单机情况下的训练效果对比,并没有训练时间的对比数据和多机实验相关的数据。

参考资料
1、Ad Click Prediction: a View from the Trenches.
